
티스토리 뷰
2022.02.08 Review
---
https://arxiv.org/pdf/2104.02243v2.pdf
Background
- Semantic Segmenation
- classifying each pixel in an image from a predefined set of classes
- Knowledge Distillation
- Process of transferring knowledge from model to other model that has different structure
- usaually, model compression method in which a small model is trained to mimic a pre-trained, larger model
- start to research for adapt different domain
- Process of transferring knowledge from model to other model that has different structure

- Indoor Scene Parsing
- Important role in many application. such as robot navigation, Augmented Reality
- Challenging
- including distorted object shapes, severe occlusions, viewpoint variations, and scale ambiguities
- Previous approach
- use geometric information
- leverage additional geometric information to obtain structured information (typically use the depth map)
- require the availability of the depth map inputs not only in the training but also in the testing
- limited applicability to general situations, in which depth is not available
- use geometric information

3D-to-2D Distillation for Indoor Scene Parsing
Goal
- Enhance 2D features extracted from RGB images using by 3D features extracted from largescale 3D data repositories for indoor scsene parsing

Contribution
- Distill 3D knowledge from a pretrained 3D network to supervise a 2D network
- Design a two-stage dimension normalization method to calibrate the 2D and 3D features for better integration
- Design a semantic-aware adversarial training model to extend our framework for training with unpaired 3D data
Detail
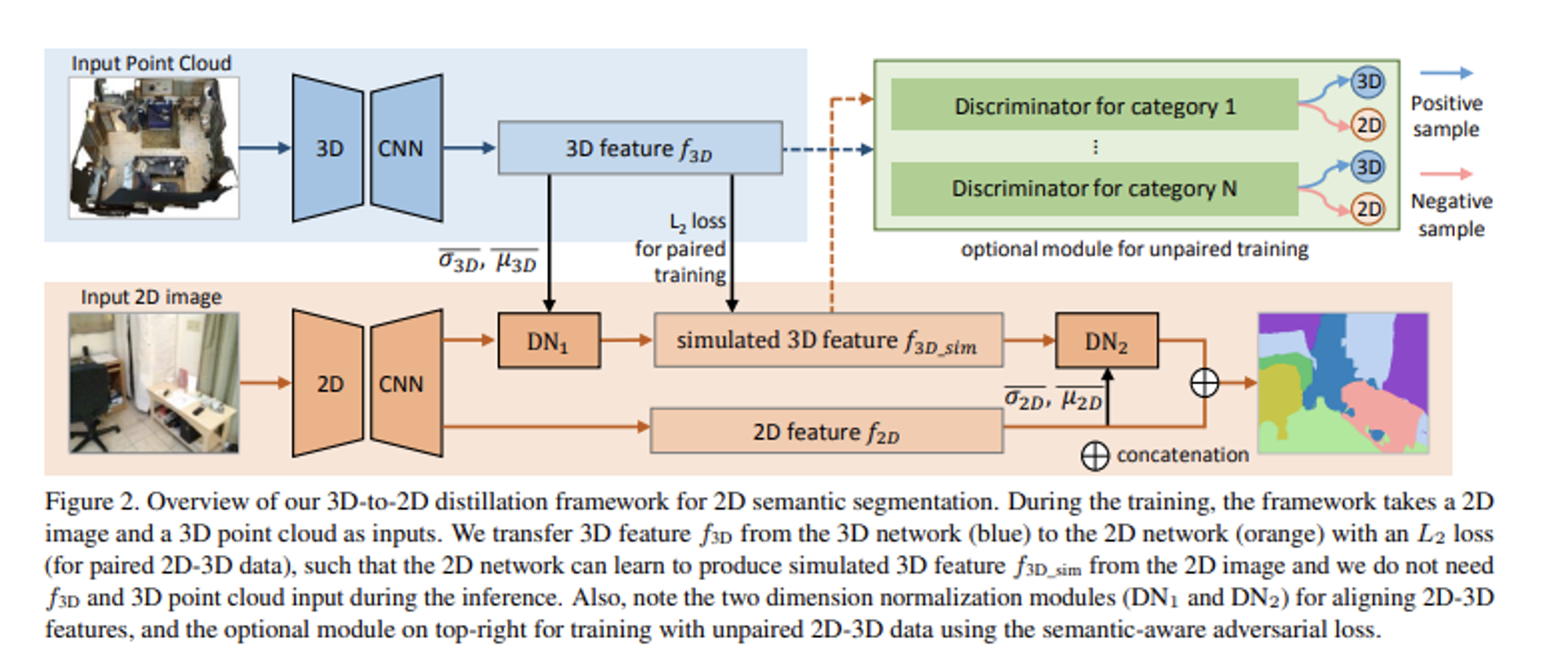
- 3D-to-2D distillation framework
- Framework
- Train input : 2D image, 3D Point Cloud
- Extract each feature using by 3D CNN, 2D CNN
- train to produce simulated 3D feature $f_{3d\_sim}$ from 2D CNN with dimension normalization
- concat 3D & 2D feature to generate segmentation map
- with unpaired dataset, adversarial Training with discriminator
- 3D-to-2D distillation
- Training the network to learn to simulate 3D features from 2D feature of the input image
- if paired 2D-3D data is available in the training
- can determine the pixel location associated with each point in the input point cloud
- L2 regression loss between $f_{3d}$ and $f_{3d\sim}$ to supervise the generation of $f{3d\_sim}$ in the 2D network

- To train the whole framework for the semantic segmentation task
- use cross entropy loss.

- use cross entropy loss.
- Dimension Normalization
- Reduce the numerical distribution gap between the 2D and 3D features, as they are from different data modalities and neural network models



- $µ$ , $σ$ : channel-wise means and variances of the feature map over the N, H, and dimensions
- The purpose of DN1 is to transform the input 2D feature to align its distribution with that of the 3D feature for effective feature learning
- The purpose of DN2 is to calibrate the learned 3D feature f3D_sim back to f2D for smooth 2D-3D feature concatenation
- Adversarial Training with Unpaired Data
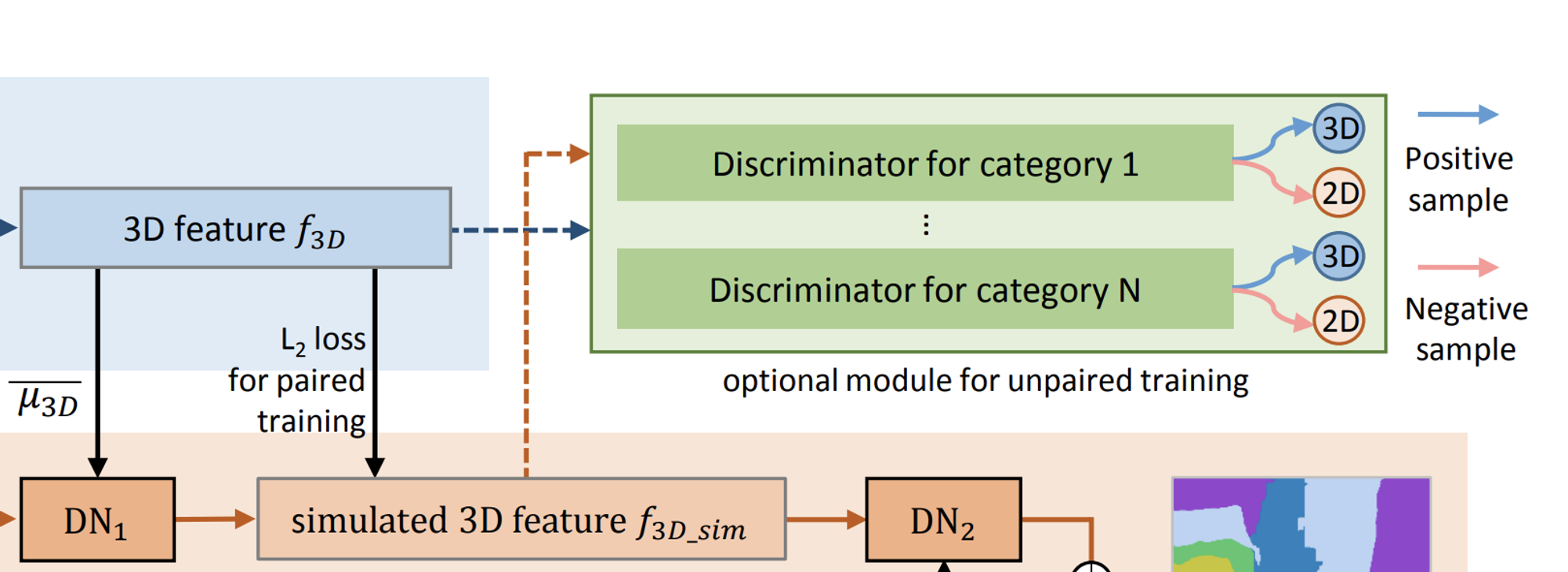
- paired 2D-3D data are typically expensive to acquire in a large quantity
- design a new adversarial training approach to correlate 2D and 3D features and supervise the generation of the simulated 3D features without pair
- key insight
- existing indoor 2D and 3D datasets usually have common object categories
- propose a novel adversarial training model with a per-category discriminator
- determines whether the feature is a real 3d feature or is generated from a 2d cnn
- Goal
- the 2D network should learn to generate simulated 3D features solely without requiring paired 2D-3D data, such that the discriminator cannot differentiate the 3D features from the simulated one of the same category
- Discriminator
- Each discriminator using six fully-connected layers
- Input : $f_{3d}$ or $f_{3d\_sim}$
- Predict a confidence score that indicates whether the input feature vector comes from the 2D or 3D network.
- Adversarial Train
- $Φ_{2d}$ : 2D network that generate $f_{3d\_sim}$
- $D_c$ : Discriminator for category c
- similar to the way the generator (like


- where Nc,i (or Mc,j ) equals 1, if the 2D pixel i (or 3D point j) belongs to category c
- Framework
Experiments
- Dataset:
- 3D, 2D : ScanNet-v2, S3DIS
- only 2D : NYUv2
- Can change Segmentation, 3D CNN archtecture
- Comparing
- Comparing with Related Geometry-Assisted and Knowledge Distillation Methods


- Baseline
- the original PSPNet-50 model ( just segmentation )
- Multitask : predict a depth map (supervised), 2d feature
- Cascade : SOTA Depth prediction 결과와 함께 Segmentation
- Geo-aware : distills features from depth maps for assisting 2D semantic segmentation
- KD : most recent knowledge distillation approach for semantic segmentation
- Outperforms all of them
- the simulated 3D features leads to better results than explicitly predicting a depth map
- 3D-to-2D distillation approach can lead to a higher performance than simply adopting a general knowledge distillation model
- Further Evaluations with Sparse Paired Data


- can easily incorporate it into existing semantic segmentation architecture.
- 3D-to-2D Distillation without Paired Data
- NYU-v2 as the 2D data, ScanNet-v2 as the 3D data to train

- Distill unpaired 3D data to enrich features in the 2D network
Analysis

- occlusions (Figure 5: door, bathtub and toilet, Figure 6: chair and table),
- uncommon viewpoints (Figure 5: table)
- confusions due to similar color and texture (Figure 6: column, and chair)
- Utilize 3D information
- This approach facilitates the 2D network to better utilize 3D information when constructing the deep features.
- Generalization domain abilities
- the embedded 3D information in deep features may help the CNN better utilize the robust 3D cues, such as shape, for recognition, and further improve the model’s
- trained in ScanNet, Tested in NYU

Conclusion
- presents a novel 3D-to-2D distillation framework that effectively leverages 3D features learned from 3D point clouds to enhance 2D networks for indoor scene parsing
- 2D network can infer simulated 3D features without any 3D data input
- propose a two-stage distillation normalization module for effective feature integration
- To bridge the statistical distribution gap between the 2D and 3D features
- Extend framework for training with unpaired 2D-3D data
- design an adversarial training model with the semantic aware adversarial loss
How can we use
- our warehouse has similiar environment with indoor. they has typical 3d structure
- Indoor ( Floor, Pillar, Ceiling .. )
- Structure ( Rack, Package.. )
- leverage our 3d structure knowledge
- We have some sources to get 3D data
- Lidar mapping
- 3D synthetic warehouse
- We can use this 3d data in our training, and we can infer in motionkit without 3d data
- If 3D feature help to make Generalization, It can adopt other warehouse easily.
- Keep following!
'Paper Review' 카테고리의 다른 글
댓글