
티스토리 뷰
Paper Review
[Review] YOLOv7 Review, Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
꿈꾸는컴퓨터 2023. 12. 21. 17:492022.10.13에 직접 리뷰 했던 것을 좀 지나서 블로그에 올립니다. 최신 정보는 아닌 점 참고 바랍니다.
YOLO (You Only Look Once)

- Single stage real-time object detector
- Performance, Accruate, Active community
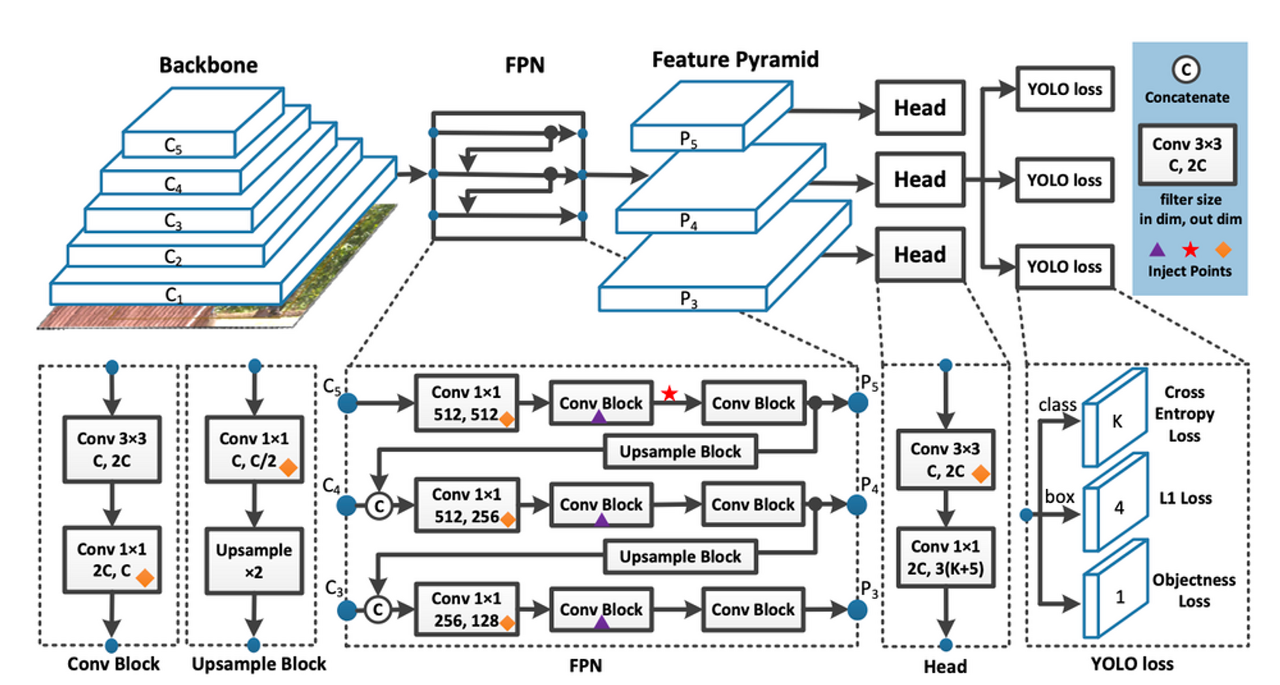
- featurized through a backbone, combined and mixed in the neck, passed along to the head

YOLO-v7

- AlexeyAB, WongKinYiu
- AlexeyAB took up the YOLO torch from the original author. Joseph Redmon, when Redmon quit the CV industry due to ethical concerns
- Scaled-YOLOv4, YOLOR, YOLOv6
SOTA Real-time object detector

- beat Tranformer, ConvNext
- vs ‘transformer based’ (SWIN-L Cascade-Mask R-CNN)
- 509% in speed and 2% in accuracy
- vs ‘convolution based’ (ConvNeXt-XL Cascade-Mask R-CNN)
- 551% in speed and 0.7% AP in accuracy
- also DETR, YOLOR, YOLOX, Scaled-YOLOv4, Deformable DETR,,,
- vs ‘transformer based’ (SWIN-L Cascade-Mask R-CNN)
- Contribution
- Design new trainable bag-of-freebies
- Optimized modules and optimization methods which may strengthen the training cost for improving the accuracy of object detection, but without increasing the inference cost
- more robust loss function
- more efficient label assignment method
- more efficient training method
- Optimized modules and optimization methods which may strengthen the training cost for improving the accuracy of object detection, but without increasing the inference cost
- Propose new archtiecture for real-time object detector & corresponding model scailing method
- Design new trainable bag-of-freebies
Trainable bag-of-freebies
1. Planned re-parameterized convolution
- Model re-parameterization
- merge multiple computational modules into one at inference stage
- model-level ensemble
- train multiple identical models with different training data, and then average the weights of multiple trained models
- weighted average of the weights of models at different iteration number
- module-level re-parameterization
- splits a module into multiple identical or different module branches during training and integrates multiple branched modules into a completely equivalent module during inference
- RepNet


-
- training time -> multi-branch
- inference time -> re-parameterization : single branch
- nice performance in VGG, but not in Resnet, DenseNet

-
- use RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterized convolution
- identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet
- duplicated identity connection and residual connection
- identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet
- use RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterized convolution
2. Coarse for auxiliary and fine for lead loss

- Deep supervision
- Add extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide

- Improve the deep supervision
- consider together with the ground truth to use some calculation and optimization methods to generate a reliable soft label
- Call the mechanism that considers the network prediction results together with the ground truth and then assigns soft labels as “label assigner.”
- (c) Independent assigner
- previous approach
- (d) Lead head guided label assigner
- calculated based on the prediction result of the lead head and the ground truth, and generate soft label through the optimization process
- shallower auxiliary head directly learn the information that lead head has learned, lead head will be more able to focus on learning residual information that has not yet been learned.
- (e) Coarse-to-fine lead head guided label assigner
- lead head prediction as guidance to generate coarse-to-fine hierarchical labels, which are used for auxiliary head and lead head learning
- Coarse label : allowing more grids → focus on optimizing the recall of auxiliary head
- Fine label : same with (c)
- It makes the optimizable upper bound of fine label always higher than coarse label.
- if auxiliary head learns lead guided soft label, it will indeed help lead head to extract the residual information from the consistant targets
- lead head prediction as guidance to generate coarse-to-fine hierarchical labels, which are used for auxiliary head and lead head learning

Architecture
1. Extended efficient layer aggregation networks

- How to design an efficient network? → By controlling the shortest longest gradient path, a deeper network can learn and converge effectively
- CSPVoVNet analyzes the gradient path, in order to enable the weights of different layers to learn more diverse features
- E-ELAN uses expand, shuffle, merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path
- use group convolution to expand the channel and cardinality of computational blocks
2. Model scaling for concatenation-based models
- Purpose
- adjust some attributes of the model and generate models of different scales to meet the needs of different inference speeds

- scale example in EfficientNet (width, depth, resolution)

- when scaling up or scaling down is performed on depth, the in-degree of a translation layer which is immediately after a concatenation-based computational block will decrease or increase
- cannot analyze different scaling factors separately for a concatenation-based model but must be considered together
- propose the corresponding compound model scaling method for a concatenation-based model
- When we scale the depth factor of a computational block, we must also calculate the change of the output channel of that block
Experiments
- COCO dataset
- Edge GPU / normal GPU / cloud GPU → YOLOv7-tiny, YOLOv7, YOLOv7-W6
- compound scaling up → YOLOv7-X, YOLOv7-E6, YOLOv7-D6
- E-ELAN + YOLOv7-E6 → YOLOv7-E6E

ETC
- github 6.2k stars, very active community
- support to export tensorRT
'Paper Review' 카테고리의 다른 글
| [Review] A Review of Video Object Detection: Datasets, Metrics and Methods (0) | 2023.12.27 |
|---|---|
| [Review] Class-agnostic Object Detection (1) | 2023.12.27 |
| [Review] 3D-to-2D Distillation for Indoor Scene Parsing (1) | 2023.12.27 |
| [Review] Unity Perception: Generate Synthetic Data for Computer Vision (1) | 2023.12.27 |
댓글