
티스토리 뷰
[Review] A Review of Video Object Detection: Datasets, Metrics and Methods
꿈꾸는컴퓨터 2023. 12. 27. 23:362021.11.30 Review
https://pdfs.semanticscholar.org/87db/49a14a1dd0e3d672e1144dc13354d892558d.pdf
https://www.semanticscholar.org/paper/A-Review-of-Video-Object-Detection%3A-Datasets%2C-and-Zhu-Wei/3c03cb37863eea4be5e01f407d6899620dc4d254?p2df
www.semanticscholar.org
---
Shortcomings of frame by frame basis object detection in video
- lack of computational efficiency due to redundancy across image frames or by not using a temporal and spatial correlation of features across image frames
- lack of robustness to real-world conditions such as motion blur and occlusion
Approach
- make use of the spatial-temporal information to improve accuracy
- ex) Li, H.; Yang, W.; Liao, Q. Temporal Feature Enhancing Network for Human Pose Estimation in Videos.
- reducing information redundancy and improving detection efficiency
- ex) Li, M.; Sun, L.; Huo, Q. Dff-Den: Deep Feature Flow with Detail Enhancement Network for Hand Segmentation in Depth Video
- Jointly detecting and multiple people tracking by semantic and scene information
- Approachs
- flow-based
- LSTM-based
- attention-based
- tracking-based
- other methods
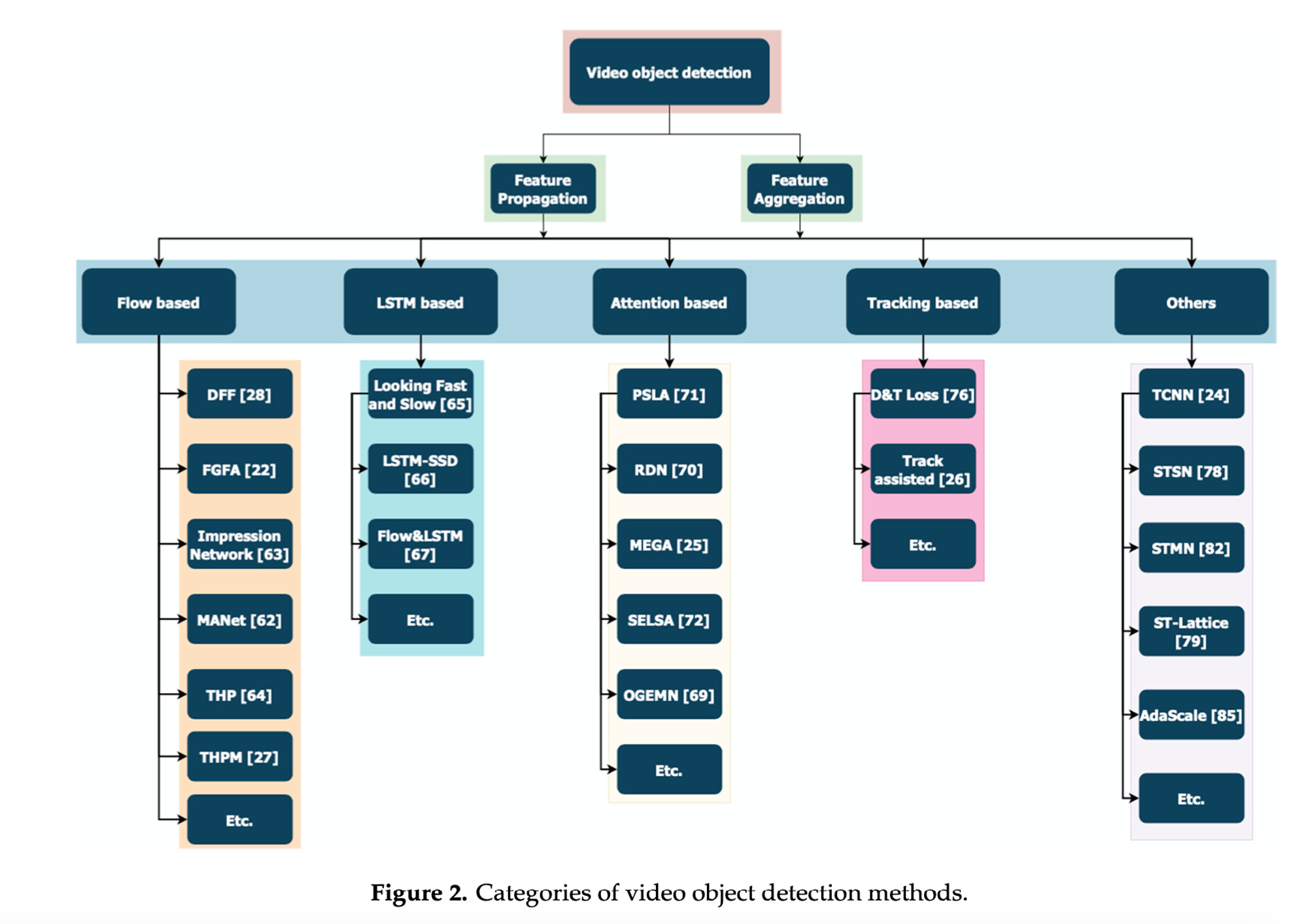
Methods
1. Flow-based
1-1. Save computation
- Deep Feature Flow for Video Recognition, 2017, IEEE

- extract feature map on key frame, ResNet-101
- Features on non-key frames were obtained by warping the feature map on key frames with the flow field generated by FlowNet
- 73.1 mAP, 20fps ← 73.9%, 4fps, K40
1-2. Improve Detection Accuracy
- FGFA: Flow-Guided Feature Aggregation for Video Object Detection, 2017, IEEE
- In order to enhance the feature maps of a current frame, the feature maps of its nearby frames were warped to the current frame according to the motion information obtained by the optical flow network

- warped feature maps and extracted feature maps on the current frame were then inputted into a small sub-network to obtain a new embedding feature

- 76.3% mAP, 1.36fps
1-3. improve both accuracy and computational speed
- Impression Network for Video Object Detection, 2017

- use keyframe, non-key frame
- use aggregation
- 75.5%, 20fps
- Towards High Performance Video Object Detection

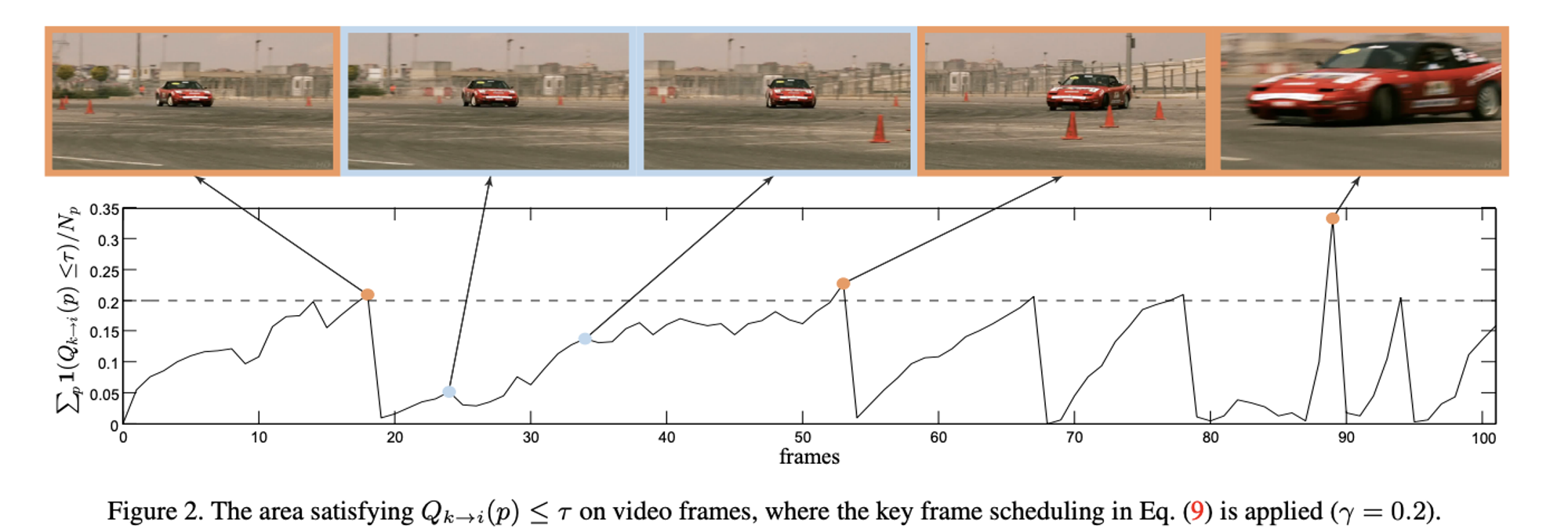
- temporally adaptive key frame scheduling to further improve the trade-off between speed and accuracy.
- the fixed interval key frames were adjusted in a dynamic manner according to the proportion of points with poor optical flow quality
- mAP 76.8%, 15.4fps
- MobileNet version → 60.2%, 25.6fps on mobiles
2. LSTM-based
- LSTM was employed to process sequential data and select important information for a long duration.
- offline LSTM-based solutions - which utilize all the frames in the video.
- online solution - it only uses the current and previous frames.
- I = video frame, S = State unit, D = Detection outcome

- Convolutional LSTM layer
- Mobile Video Object Detection with Temporally-Aware Feature Maps, 2018, IEEE

- Two feature extractors were used alternately.

- improve accuarcy, also faster than mobilenet
- Mobile Video Object Detection with Temporally-Aware Feature Maps, 2018, IEEE
- for online detection
- Modeling Long—And Short-Term Temporal Context for Video Object Detection, 2019, IEEE

- use flow to warp feature
- short-term temporal information was utilized by warping the feature maps from the previous frame → sometimes image distortion or occlusion would last for several video frames
- Feature map to LSTM
- long-term temporal context information was also exploited via the convolutional LSTM
- aggregated all of them
- 75.5%
3. Attention-based
- requires a large amount of memory and computational resources. In order to decrease the computational resources, an attention mechanism was introduced for feature map alignment
3-1. Local temporal information
- Relation Distillation Networks for Video Object Detection, 2019, IEEE
- extract feature maps and object proposals are generated with the help of a Region Proposal Network (RPN)
- Relation Distillation Networks to progressively schedule relation distillation for enhancing detection via a multi-stage reasoning structure, which contains basic stage and advanced stage

- Relation
- relation module is devised to enhance each proposal by measuring relation features as the weighted sum of appearance features from other proposals
- Relation Networks for Object Detection, 2018, CVPR


- mAP 81.7% (Resnet-101), 10.6fps in V100
3-2. Entire sequence level
- Sequence Level Semantics Aggregation for Video Object Detection, 2019, ICCV
- features of the proposals were extracted on different frames and then a clustering module and a transformation module were applied.

- Object Guided External Memory Network for Video Object Detection, 2019, ICCV
- used object-guided external memory to store the pixel and instance level features for further global aggregation.
- only the features within the bounding boxes were stored for further feature aggregation
-

3-3. Memory Enhanced Global-Local Aggregation for Video Object Detection, CVPR,2020
- Utilizing the global and local information inspired by how humans go about object detection in video using both global semantic information and local localization information
- When it was difficult to determine what the object was in the current frame
- The global information was utilized to recognize a fuzzy object according to a clear object with a high similarity in another frame
- mAP 82.9 %, 8.73fps in 2080ti


3-4. Progressive Sparse Local Attention for Video object detection, ICCV, 2019
- the spatial correspondence between features across frames in a local region with progressively sparser stride and uses the correspondence to propagate features

- propose PSLA(Progressive Sparse Local Attention) and use key-frame skills
- 81.4 mAP, 26.0 fps(80.0 mAP), (Titan V)
4. Tracking-Based
- Detect objects on fixed interval frames and track them in frames in between.
4-1. Cooperative Detection and Tracking for Tracing Multiple Objects in Video Sequences,2016,ECC

- combining detection and tracking for video object detection
- objects were detected by the image object detector
- detected object was tracked by the forward tracker
- undetected objects were stored by the backward tracker
- conducts the backward tracking to recover more missing states and refine the target trajectories.
- tracking
- make candidate, encoding to feature vector, use RGB historgram and HOG historgram
4-2. : Cascaded Tracked Detector for Efficient Object Detection from Video


- Method
- Every frame is inputted to a proposal network to output potential proposals in the frame.
- Object position in a next frame is predicted with a high confidence using the tracker.
- In order to obtain the calibrated object information, the outputs of the tracker and the proposal network are combined and inputted to a refinement network
- Tracker was used to predict the positions on the next frame with the historical information
4.3. Detect to Track and Track to Detect, 2017, ICCV


- correlation → flownet
- mAP 80.0%
4.4. Detect or Track: Towards Cost-Effective Video Object Detection/Tracking, 2018, AAAI
Detect or Track: Towards Cost-Effective Video Object Detection/Tracking | Proceedings of the AAAI Conference on Artificia
ojs.aaai.org

5. Others
- Attentional LSTM
- Single-Shot Detector Based on Attention and LSTM, 2018, IEEE
- deformable convolution is employed for feature alignment
- Object Detection in Video with Spatiotemporal Sampling Networks, 2018, ECCV
- The Spatial-Temporal Memory Network (STMN) operates in an end-to-end manner to model the long-term information and align the motion dynamics for video object detection
- Video Object Detection with an Aligned Spatial-Temporal Memory
- Research of Image sizes
- Towards Real-time Video Object Detection Using Adaptive Scaling, 2019
Comparison
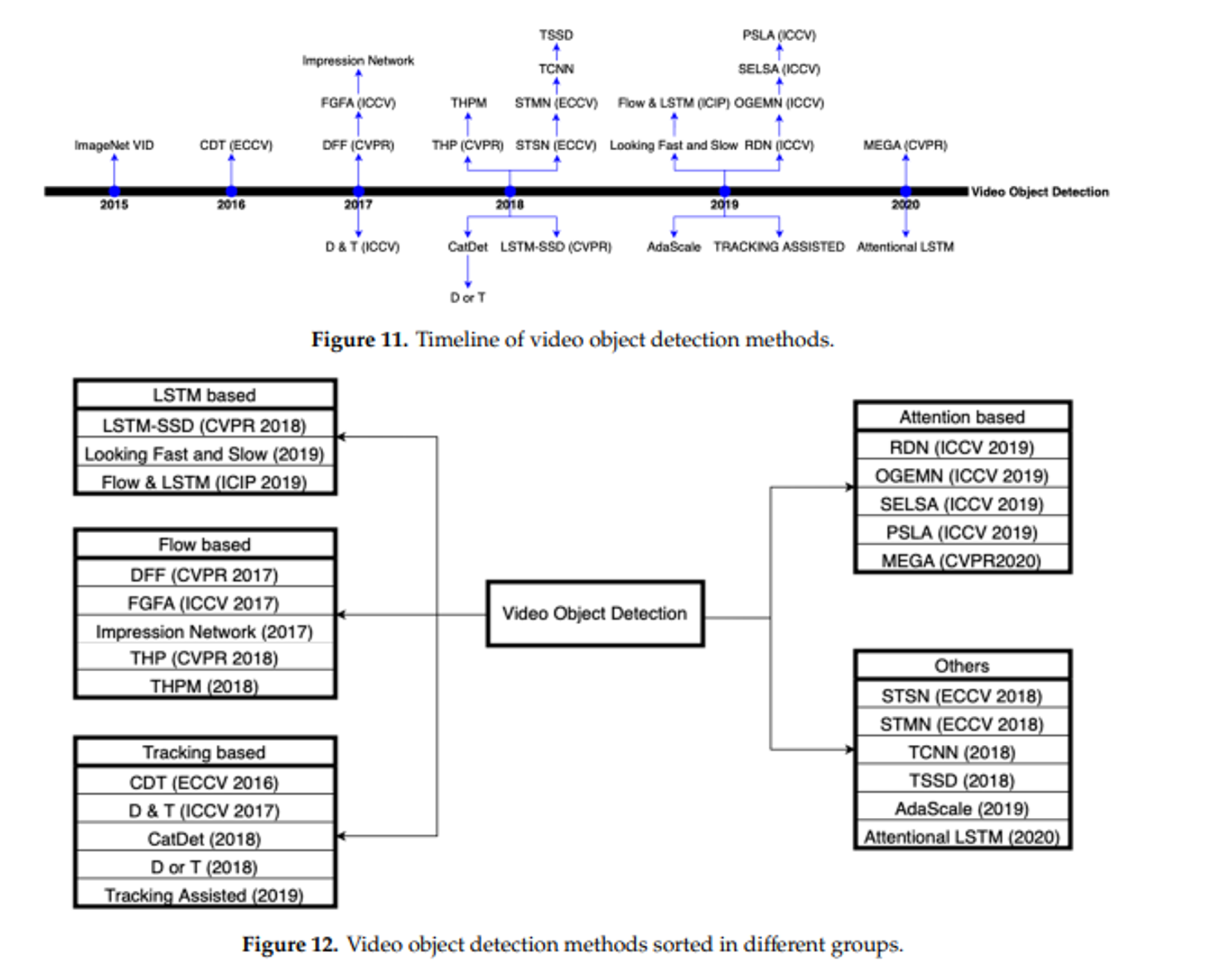
- the methods based on optical flow were proposed earlier. During the same period, video object detection methods were assisted by tracking due to the effectiveness of tracking in utilizing the temporal–spatial information
- the optical flow-based methods needed a large number of parameters and they were only suitable for small motions.
- optical flow reflects pixel level displacement, it has difficulties when it is applied to high-level feature maps. One pixel movement on feature maps may correspond to 10 to 20 pixels movement.
- The latest research is mostly based on attention, LSTM or a combination of methods such as Flow&LSTM
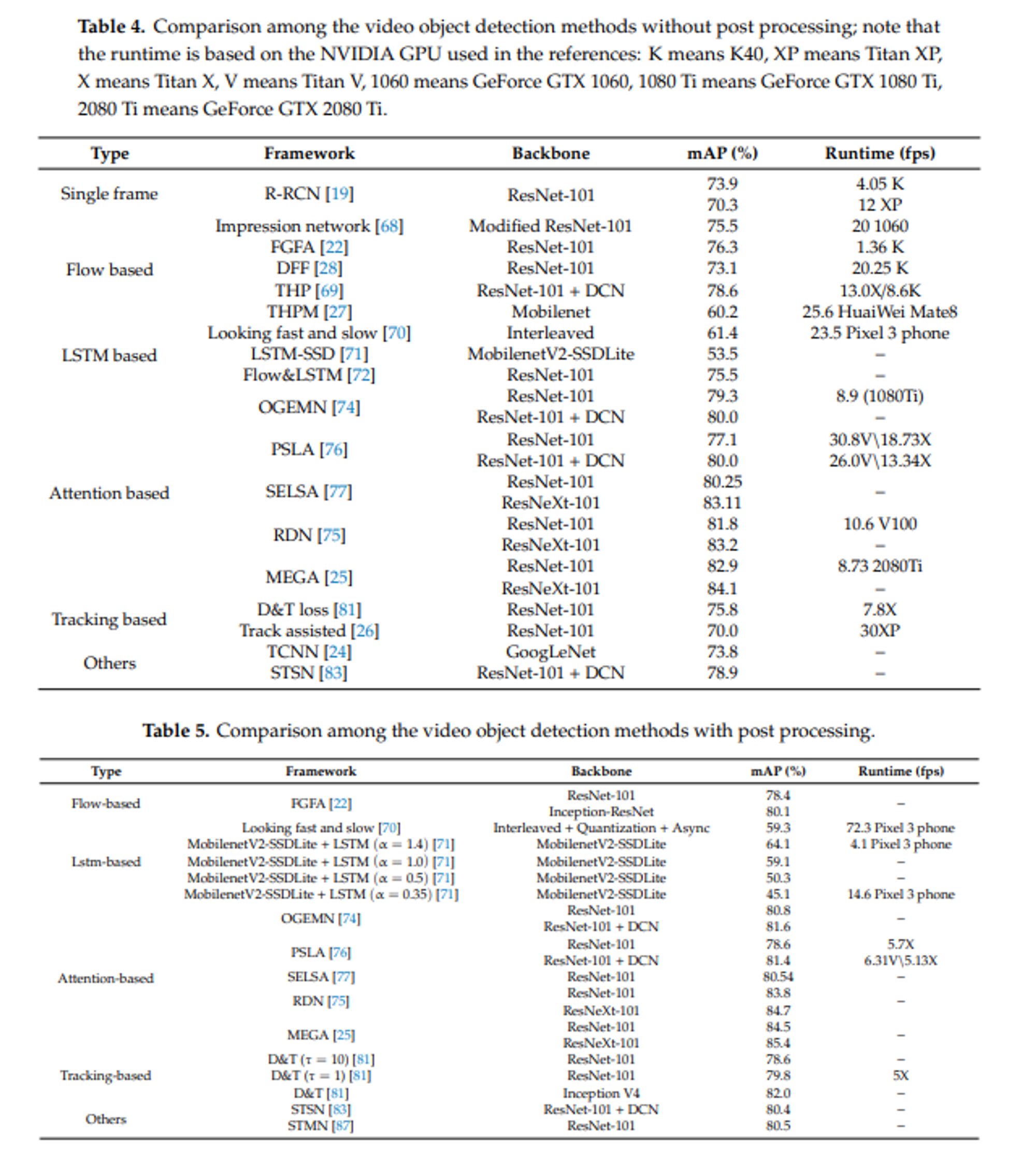
- LSTM captures the long-term information with a simple implementation
- a slow state decay and thus loss of long-term dependence is resulted
- Attention-based methods also show the ability to perform video object detection effectively
- Attention-based methods aggregate the features within proposals that are generated. This decreases the computation
- With post-processing, the accuracy is noticeably improved
- For example, the accuracy of MEGA is improved from 84.1% to 85.4% mAP.
Future Trend
- ImageNet VID, does not include complex real-world conditions as compared to the static image dataset COCO
- mAP, which is derived from static image object detection. This metric does not fully reflect the temporal characteristics in video object detection ( ex : stability )
- Most of the methods covered in this review paper only utilize the local temporal information or global information separately
- for most of the existing video object detection algorithms, the number of frames used is too small to fully utilize the video information. it is of importance to develop methods that utilize the long-term video information.
- the trade-off between accuracy and speed needs to be further investigated
- the Looking Fast and Slow method achieved 72.3 fps on Pixel 3 phones, the accuracy is only 59.3%